

Generative AI in the form of AI Assistants provides effective support in preparing presentations or academic papers. They help with developing topics, accelerate literature analysis, and assist with revising texts. In parallel, AI‑supported literature research makes it possible to systematically explore large data sets, quickly identify relevant publications, and reveal complex thematic connections.
When used in a purposeful and responsible manner, AI enhances the literature research and facilitates academic work.
During idea development, AI Assistants can help find interesting topics, refine research questions and provide conceptual impulses.
Through keyword generation, AI tools enables identification and logical linking of relevant search terms to optimize literature research. In addition, they can explain technical terms, historical events, or key figures in an accessible way, helping to close knowledge gaps efficiently.
When uploading one’s own texts, AI can support by summarizing content or translating it into other languages - however, users should always ensure they only upload public documents to comply with data privacy regulations.
AI Assistants an also enhance the writing process itself by refining phrasing, improving style, or compensating for grammatical weaknesses.
General AI Assistants for brainstorming, keyword searches, topic development and structuring, term explanations include:
AI Assistants for document analysis, summaries and text explanations include:
AI Assistants for the writing process, style editing, proofreading and spell checking include:

A prompt is more than just a simple request; it is a precise tool that helps you find exactly the relevant literature titles you need. The clearer and more structured your instructions are, the more accurately and efficiently the AI will summarise a document or revise text.
1. Define Your Goal
2. Provide a Precise Initial Instruction
3. Specify the Target Audience
4. Define the Language and Writing Style
5. Clarify Your Preferred Format
6. Add Key Details
7. Assign a Role to the AI
8. Refine the Prompt Step by Step
A good prompt is the key to receiving precise and helpful answers from an AI.
It is not enough to simply ask a question, instead, you should clearly define your goal and proceed in a structured way.
Start with a precise instruction, specify the target audience, tone, and format, and add relevant details to avoid vague or overly general responses.
The iterative process is especially important: test different phrasings, ask for feedback, and gradually refine your prompts.
In this way, you can minimize AI weaknesses such as inaccurate answers or hallucinations and achieve the best possible results.
Database-supported AI tools can be divided into two categories: Finders and Connectors.
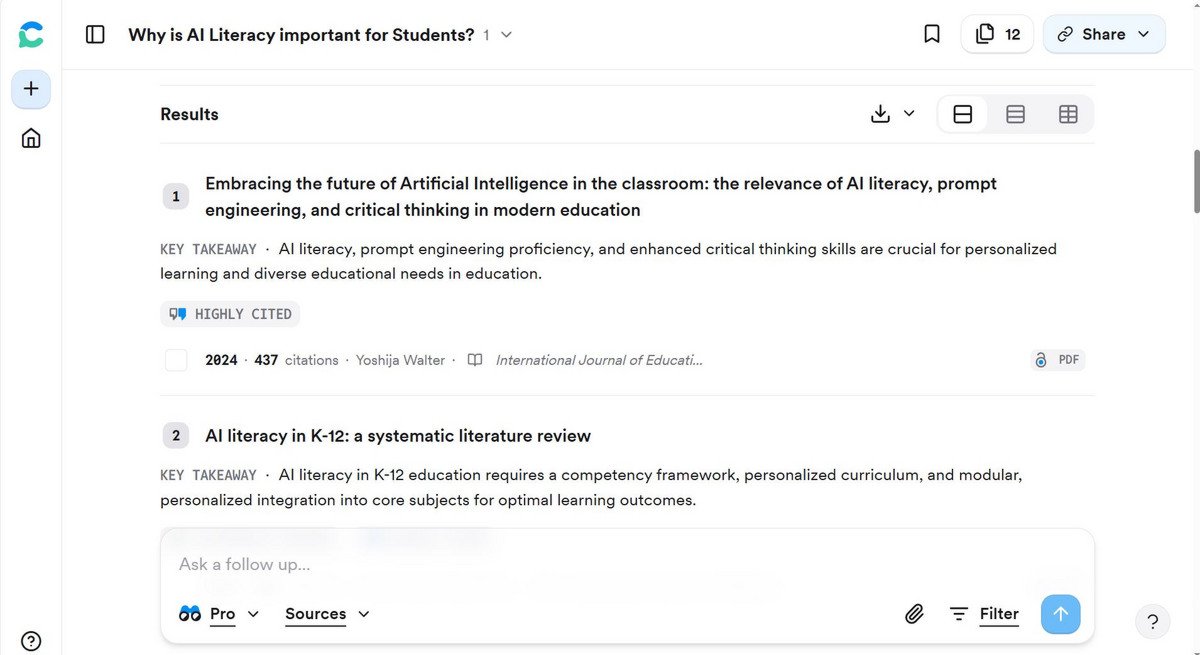
Finders identify and prioritise relevant literature based on search terms or full queries.
Connectors reveal thematic links between papers by analysing them and grouping them into clusters.
Finders operate similarly to digital library catalogues: users can enter keywords, phrases, or even complete questions and receive matching results.
These tools search metadata, abstracts, and in some cases full texts to identify and rank relevant publications.
They are particularly useful for STEM and medical research, as they primarily locate English-language Open Access articles with DOIs. However, they are less suited for humanities, social sciences, theology, or law.
Finders not only help you discover relevant literature even when you don’t know the exact technical terms, but they also support comparing, summarizing, and preparing content.
Automated additional features such as abstracts generation, tabular extractions, or reading aids (e.g., highlights, translations) can speed up the research process.
Compared to traditional databases like Web of Science, BASE, or Google Scholar, Finders also offer more intuitive, natural‑language queries and time‑saving summaries.
However, paywalled works or recent non‑English monographs are difficult or nearly impossible to find. The number of results is often smaller than in traditional databases -especially when dealing with paid content or literature that is less well covered in specific fields.
In addition, the usefulness of certain extra features should be viewed critically: playful elements such as the Consensus Meter (which displays how roughly 20 of the most relevant publications evaluate a yes/no question) or deep‑research functions can provide a quick initial overview, but they are usually paid, limited to open‑access articles, based on non‑transparent ranking methods, and/or produce incomplete or biased summaries. Especially for complex research questions, such automated results can lead to misinterpretations.
Examples of Finders include:
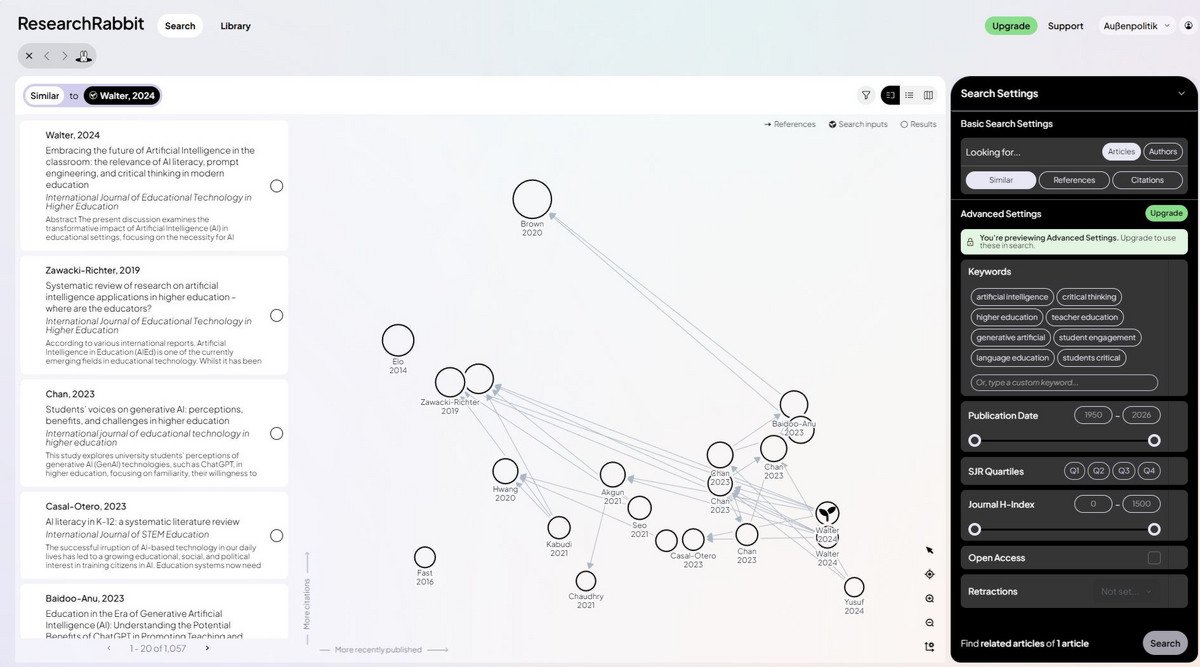
Connectors help discover thematically related literature based on a known starting paper (the “seed paper”).
This approach mirrors the snowball method of literature research.
The starting point is always a seed document, defined via DOI, title, keyword, or an uploaded PDF file. Building on this, the tool identifies publications that are directly or indirectly connected to the selected text - whether through mutual references, thematic proximity, or AI‑based similarity analyses that reveal connections not immediately visible in bibliographic data.
The results are then presented in a visual, thematically grouped cluster, making complex research areas and author networks visible at a glance. They offer an especially intuitive entry point for the humanities and social sciences.
Connectors identify bibliographically linked publications registered in databases like Crossref, OpenAlex, or Open Citations. Their particular added value lies in systematic literature review, detecting collaboration structures, and identifying works that are connected to the source text through multiple intermediary publications.
Additionally, visualizations simplify exploring new research topics and enable intuitive navigation through bibliographic networks.
Some tools (e.g., Scite, a paid service) go even further by accessing full texts and precisely highlighting how a work is cited at a specific passage (“citation statements”), enabling a more nuanced assessment of scholarly discourse.
At the same time, there are clear limitations: Their output quality depends heavily on the specific research field and the underlying data availability.
Older works without persistent identifiers, publications with sparse metadata, or print‑only literature are captured only inadequately, which reduces the informative value of the networks.
In addition, only a few filtering options are often available, meaning that bibliographic information must be checked and corrected manually because it is sometimes incomplete or incorrect. Automatic content summaries are often missing, even when abstracts are available.
Compared to established services such as Google Scholar, Connectors therefore offer no quantitative advantage, but rather an alternative, visual perspective on existing data collections.
Examples of Connectors include:
Using generative AI in academic studies and research requires transparent labelling and documentation, both to maintain transparency in one's own working methods and to meet academic standards.
If texts are generated using AI tools, they must always be identified as such; otherwise, they may be classified as attempted deception. Even though the rules for AI‑supported literature research are often less strict, it is still advisable to clearly disclose the use of AI, especially when it contributed to key steps such as literature selection or document analysis.
What matters is that academic work remains an independent achievement for which students and researchers take responsibility in terms of content and accuracy. Since requirements vary across disciplines and departments, it is essential to always follow the guidelines provided by supervising instructors.
The following explanations are intended solely as general guidance and can be used either individually or in combination:
The guidelines of common citation systems (APA, MLA, Chicago Style) provide guidance on how to clearly mark AI-generated passages as direct or indirect quotations.
Purpose:
Example in APA Style from the following APA article:
The use of AI in the research process (e.g., literature review, brainstorming, text generation, or text revision) can be explained in the introduction, the methods section, or footnotes.
Purpose:
Example of documenting AI use in formulating the research question:
A brief explanation of how AI influenced the research process can be included in the final part of the paper. This makes it possible to clearly situate the role of AI and to point out potential limitations.
Purpose:
Example for the conclusion/discussion section:
A separate documentation in the appendix provides a structured overview of AI usage, for example in tabular form with details on work step, tool used, and outcome.
Additionally, AI-generated content should be stored locally to enable future reference. This is particularly important for longer processes where the connection to original input might otherwise be lost.
Purpose:
Example:
The use of AI tools not only raises technical and legal questions, but also requires careful ethical consideration. Many AI systems are based on complex training processes, some of which take place under problematic working conditions, particularly in the Global South. Moreover, the environmental footprint of AI applications should not be underestimated - especially high‑performance models consume substantial amounts of energy and resources (The Guardian, 18.12.2025).
In addition to these challenges, it is important to question how AI-supported results are incorporated into scholarly practice without causing biases or compromising the integrity of research. A critical reflection on the implications of AI within the research process is therefore essential for ensuring responsible engagement with this technology.

To meet the challenges concerning AI, AI Literacy has established itself as an interdisciplinary approach. Its focus is on imparting knowledge and skills necessary to critically evaluate AI systems, collaborate with them, and apply them effectively in various areas of life.
In terms of information literacy, engaging with AI therefore represents an important responsibility of the university library.
AI Literacy is defined as "a set of competencies that enables individuals to critically evaluate AI technologies; communicate and collaborate effectively with AI; and use AI as a tool online, at home, and in the workplace.” (Long/Magerko 2020, p. 2)
With the adoption of the EU AI Act in May 2024, the European Union established a binding legal framework for the use of artificial intelligence. The regulations follow a 'risk-based approach', according to which applications that are considered to pose a higher risk are also subject to stricter requirements. In addition, the Act introduces transparency obligations, meaning that AI‑generated content must be clearly identified as such.
No personal, sensitive or confidential data should be entered into ChatGPT and similar platforms. On the one hand, user inputs are often stored for training purposes. On the other hand, most AI systems are hosted outside the EU, which means that GDPR-compliant use often cannot be guaranteed.
While entering bibliographic information into AI tools is unproblematic, uploading protected research data or works (e-books, essays, reviews, etc.) is considered a violation of copyright laws. Only materials that are in the public domain or published under a CC0 licence may be lawfully used with AI systems. Always check the applicable terms of use to avoid copyright infringements.
AI‑supported systems generate results on the basis of extensive but often non‑transparent datasets. It is often impossible to trace which sources were used, as the data basis is only disclosed to a limited extent.
Many tools primarily analyse freely accessible, English‑language literature, while current or discipline‑specific content may not be taken into account. Additionally, paywalled resources such as e-books, journals, or databases might also be missing from the results.
The suitability of such tools therefore varies depending on the academic field and the language involved.
Another significant issue is model bias: AI systems often reproduce prejudices or skewed patterns from the training data, which can result in inaccurate, biased, or discriminatory outputs.
Moreover, AI tools frequently generate statements that appear plausible but are in fact entirely fabricated. Because the sources of such errors are often opaque, users can rarely identify them. These so‑called 'hallucinations' exacerbate existing challenges posed by bias, as AI not only reproduces underlying distortions but also introduces additional inaccuracies.
AI tools often provide a free basic version, although registration is usually required to access it. Users seeking additional features frequently encounter paid upgrades or subscription plans.
Before selecting a tool, you should carefully evaluate which features are truly necessary for the task at hand and which pricing model aligns with your financial resources.
AI systems can facilitate certain aspects of academic work, but should not be perceived as infallible solutions. Students should also always adhere to the guidelines set by their instructors and to the examination regulations of their discipline regarding the use of AI.
AI tools often fail to capture all relevant literature titles. As a result, AI‑generated content may not be citable, may contain incorrect references (e.g., inaccurate journal titles), or may refer to works that do not actually exist, even if they appear plausible at first glance. Moreover, such outputs are not always fully aligned with scholarly standards, which can lead to unintended and distorted results.
It is therefore essential to use this technology with great care, be aware of the legal and ethical frameworks, and critically evaluate every output.
When these considerations are taken into account, AI tools can serve as useful aids in the literature research process and academic work.
Artificial Intelligence (AI) refers to systems that mimic human-like cognitive abilities – ranging from speech recognition and text generation to decision-making and problem-solving. These technologies offer promising opportunities for academic work, but they also require a critical approach.
Generative AI is the umbrella term for all AI systems that use trained statistical models to autonomously create new (though not necessarily factually accurate) content such as text, images, audio, code or videos.
Large Language Models (LLMs) like ChatGPT or Open WebUI are a subcategory of generative AI that understand, process, and generat text. They are trained on an enormous amount of textual data and have analysed billions of word combinations. LLMs generate responses solely through statistical predictions within the given query context (the so‑called prompt). Since they interpret language only as patterns of probability, they lack critical reasoning and genuine language understanding, which is why they are also referred to as “stochastic parrots” (Bender et al. 2021).
Retrieval‑Augmented Generation (RAG) can enhance AI‑supported literature research by linking large language models with external data sources such as research papers (e.g., from PubMed) or personal PDF collections. This approach produces more accurate, evidence‑based results and helps minimize the risk of incorrect or fabricated information (“hallucinations”). It is already employed in AI tools such as Perplexity, Elicit, and Semantic Scholar. The quality of the output depends on the underlying data and still requires careful critical evaluation.
The AI Tutors Passau provide personalized assistance, flexible bookings by students and instructors, and hands-on workshops.
https://www.uni-passau.de/universitaet/einrichtungen/stabsstelle-kompetenzentwicklung-in-studium-und-lehre-ksl/digitalisierung-und-ki [Content in German].










