Datenbankgestützte KI-Tools lassen sich in die beiden Kategorien Finders und Connectors einteilen.
Finders identifizieren und priorisieren passende Literatur anhand von Suchbegriffen oder ganzen Fragestellungen.
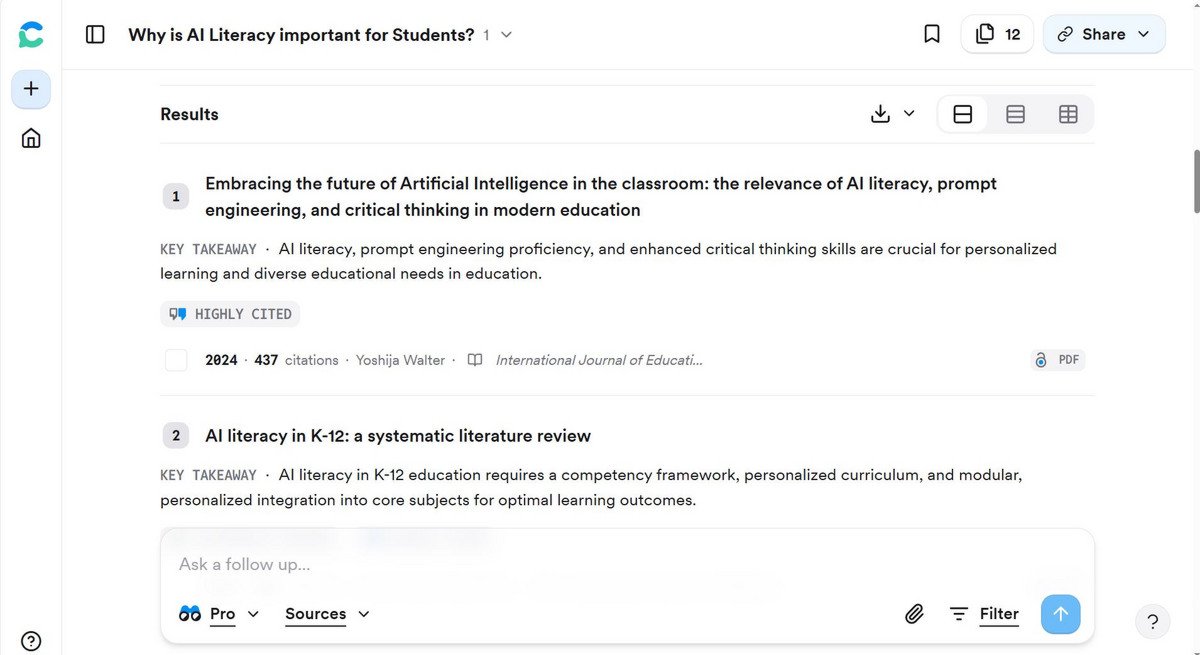
Finders funktionieren ähnlich wie digitale Bibliothekskataloge: Nutzende können Stichwörter, Phrasen oder sogar vollständige Fragen eingeben und erhalten dazu passende Treffer.
Diese Tools durchsuchen Metadaten, Abstracts und teilweise Volltexte, um relevante Publikationen zu identifizieren und zu gewichten.
Besonders hilfreich sind sie für die naturwissenschaftliche und medizinische Forschung, da sie vorwiegend englischsprachige Open-Access-Artikel mit DOI finden – weniger geeignet sind sie hingegen für Geistes- und Sozialwissenschaften, Theologie oder Jura.
Mit Finders lässt sich nicht nur passende Literatur entdecken, auch wenn die richtigen Fachbegriffe fehlen, sondern sie unterstützen auch beim Vergleichen, Zusammenfassen und Aufbereiten von Inhalten.
Automatisierte Zusatzfunktionen wie Generierung von Abstracts, tabellarische Extraktionen oder Hilfen beim Lesen (z.B. Hervorhebungen, Übersetzungen) können den Rechercheprozess beschleunigen.
Im Vergleich zu klassischen Datenbanken wie Web of Science, BASE oder Google Scholar bieten Finders zudem intuitivere, natürlichsprachige Suchanfragen und zeitsparende Zusammenfassungen.
Allerdings sind Paywall-geschützte Werke oder aktuelle nicht-englische Monografien kaum bis gar nicht auffindbar. Die Treffermenge ist oft kleiner als bei traditionellen Datenbanken – besonders, wenn es um kostenpflichtige oder fachspezifisch weniger abgedeckte Literatur geht.
Zudem sollte man die Nützlichkeit von manchen Zusatzfunktionen kritisch hinterfragen: Spielerische Features wie das Consensus Meter (zeigt auf Ja/Nein-Fragen die Bewertung durch die ca. 20 relevantesten Publikationen an) oder ‚Deep-Research‘-Funktionen können zwar einen schnellen ersten Überblick liefern, sind zumeist aber kostenpflichtig, auf OA-Artikel beschränkt, basieren auf intrasparenten Ranking-Methoden, und/oder liefern unvollständige bzw. verzerrte Zusammenfassung. Vor allem bei komplexen Fragestellungen können solche automatisierten Ergebnisse zu Fehlinterpretationen führen.
Beispiele für Finders sind u. a.:
AbsClust; Ai2 Paper Finder; Ai2 Scholar QA; Consensus; Elicit; Evidence Hunt; Google Scholar Labs; Keenious; ORKGAsk; R Discovery; ScholarInbox; ScienceOS; Scinapse; SciSpace; Semantic Scholar; Undermind
Connectors stellen thematische Verbindungen zwischen Literaturtiteln her, indem sie diese analysieren und in Clustern gruppieren.
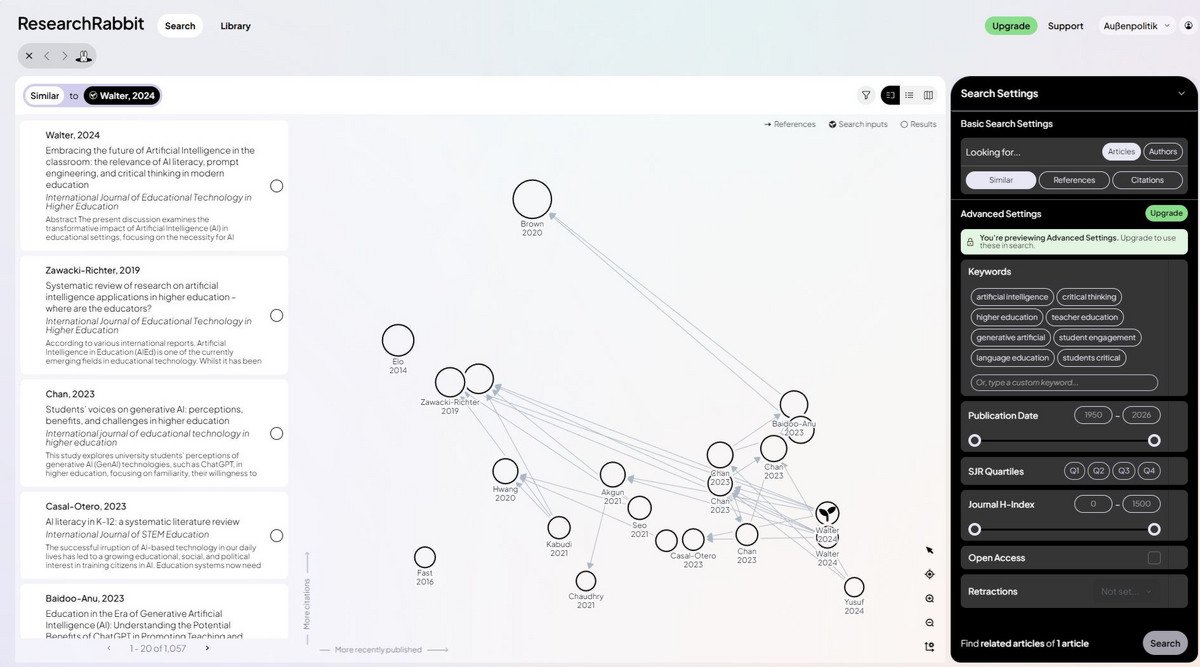
Connectors helfen dabei, thematisch verwandte Literatur auf Basis eines bereits bekannten Ausgangspapers („Seed Paper“) zu finden.
Damit ähnelt das Vorgehen der Recherche nach dem Schneeballsystem.
Ausgangspunkt ist stets ein Startdokument, das über DOI, Titel, Schlagwort oder eine hochgeladene PDF-Datei definiert wird. Darauf aufbauen identifiziert das Tool Publikationen, die in direkter oder indirekter Verbindung zum gewählten Text stehen – sei es durch wechselseitige Referenzen, thematische Nähe oder KI‑gestützte Ähnlichkeitsanalysen, die auch Verbindungen sichtbar machen, die bibliografisch nicht unmittelbar erkennbar sind.
Die Ergebnisse werden dann in einer visuellen, thematisch gruppierten Cluster präsentiert, was komplexe Forschungsschwerpunkte und Netzwerke von Autorinnen und Autoren auf einen Blick erkennbar macht. Besonders für Geistes- und Sozialwissenschaften bieten sie einen intuitiven Einstieg.
Connectors finden bibliograpfisch verknüpfte Publikationen, die z. B. in Crossref, OpenAlex oder Open Citations registriert sind. Ihr besonderer Mehrwert liegt in der systematischen Literaturrecherche, dem Erkennen von Kooperationsstrukturen oder der Identifikation von Literatur, die über mehrere Zwischenstationen mit dem Ausgangstext verbunden ist.
Zudem erleichtern die grafischen Darstellungen den Einstieg in neue Themenfelder und bieten ein intuitives Navigieren durch bibliografische Netzwerke.
Sie bieten sowohl für Personen, die sich zu Beginn ihrer Literaturrecherche einen schnellen Überblick verschaffen möchten, als auch für jene, die am Ende des Prozesses noch gezielt bislang übersehene Publikationen identifizieren wollen, einen klaren Mehrwert.
Einige Tools bieten kostenpflichtige Funktionen an, die auf Volltexte zugreifen und markieren, wie ein Werk an einer bestimmten Textstelle zitiert wird („Citation Statements“). Das kann eine differenzierte Einschätzung wissenschaftlicher Diskurse unterstützen.
Gleichzeitig bestehen klare Grenzen: Die Qualität der Ergebnisse hängt stark vom jeweiligen Forschungsfeld und der zugrunde liegenden Datenlage ab.
Ältere Werke ohne dauerhafte Identifikatoren, Publikationen mit spärlichen Metadaten oder ausschließlich gedruckte Literatur werden nur unzureichend erfasst, was die Aussagekraft der Netzwerke mindert.
Zudem stehen häufig nur wenige Filteroptionen zur Verfügung, sodass Literaturangaben manuell überprüft und korrigiert werden müssen, da sie teilweise unvollständig oder fehlerhaft sind. Eine automatische inhaltliche Zusammenfassung fehlt oft, auch wenn vorhandene Abstracts angezeigt werden.
Im Vergleich zu etablierten Diensten wie Google Scholar bieten Connectors daher keinen quantitativen Vorteil, sondern vor allem eine alternative, visuelle Perspektive auf vorhandene Datenbestände.
Beispiele für Connectors sind u. a.:
Research Rabbit; Connected Papers; LitMaps; Open Knowledge Maps; Inciteful; Local Citation Network; Scite










