

Generative KI in Form von KI-Assistenten bieten effektive Unterstützung bei der Erarbeitung von Referaten oder Hausarbeiten. Sie helfen bei der Themenentwicklung, beschleunigen die Literaturanalyse und assistieren bei der Textüberarbeitung. Paralell lassen sich mit Hilfe von KI-gestützer Literaturrecherche große Datenbestände systematisch durchsuchen, relevante Publikationen schnell identifizieren und komplexe thematische Zusammenhänge sichtbar machen.
Gezielt und verantwortungsbewusst eingesetzt, optimiert KI die Literaturrecherche und erleichtert das wissenschaftliche Arbeiten.
Bei der Ideenentwicklung können KI-Assistenten helfen, interessante Themengebiete zu finden, Forschungsfragen zu präzisieren und Denkanstöße zu liefern.
Durch die Schlagwortgenerierung lassen sich relevante Suchbegriffe identifizieren und sinnvoll verknüpfen, um die Literaturrecherche zu optimieren. Zudem können KI-Tools Fachbegriffe, historische Ereignisse oder zentrale Personen verständlich erklären und so Wissenslücken effizient schließen.
Beim Datenupload eigener Texte kann KI assistieren, indem sie Inhalte zusammenfasst oder in andere Sprachen übersetzt – allerdings sollte man immer darauf achten, nur öffentliche Dokumente hochzugeladen, um Datenschutzrichtlinien einzuhalten.
Zudem lässt sich der eigene Schreibprozess durch Textoptimierung mit KI-Assistenten verbessern, indem sie Formulierungen präziser gestalten, den Stil verbessern oder grammatikalische Schwächen ausgleichen können.
Allgemeine KI-Assistenten für die Ideenfindung, Schlagwortsuche, Themenentwicklung und Gliederung, Begriffserklärung sind u. a.:
KI-Assistenten für die Dokumentenanalyse, Zusammenfassungen und Texterläuterungen sind u. a.:
KI-Assistenten für den Schreibprozess, Stilüberarbeitung, Lektorat und Rechtschreibprüfung sind u. a.:

Ein Prompt ist mehr als nur eine einfache Suchanfrage. Er ist ein präzises Werkzeug, das Ihnen hilft, genau die relevanten Literaturtitel zu finden, die Sie benötigen. Je klarer und strukturierter Ihre Anweisung formuliert ist, desto gezielter und effizienter stellt die KI die Zusammenfassung eines Dokuments bereit oder führt Textüberarbeitungen durch.
1. Definieren Sie Ihr Ziel
2. Stellen Sie eine präzise erste Anweisung
3. Geben Sie die Zielgruppe vor
4. Legen Sie Sprach- und Schreibstil fest
5. Berücksichtigen Sie Formalitäten
6. Ergänzen Sie relevante Details
7. Weisen Sie der KI eine Rolle zu
8. Verfeinern Sie den Prompt schrittweise
Ein guter Prompt ist der Schlüssel, um von einer KI präzise und hilfreiche Antworten zu erhalten.
Es reicht nicht aus, einfach nur eine Frage zu stellen, sondern Sie sollten Ihr Ziel klar definieren und strukturiert vorgehen.
Beginnen Sie mit einer präzisen Anweisung, legen Sie Zielgruppe, Sprachstil und Format fest und ergänzen Sie relevante Details, um unklare oder allgemeine Antworten zu vermeiden.
Besonders wichtig ist der iterative Prozess: Testen Sie verschiedene Formulierungen, lassen Sie sich Feedback geben und passen Sie Ihre Prompts schrittweise an.
Auf diese Weise können Sie KI-Schwächen wie ungenaue Antworten oder Halluzinationen minimieren und die bestmöglichen Ergebnisse erzielen.
Datenbankgestützte KI-Tools lassen sich in die beiden Kategorien Finders und Connectors einteilen.
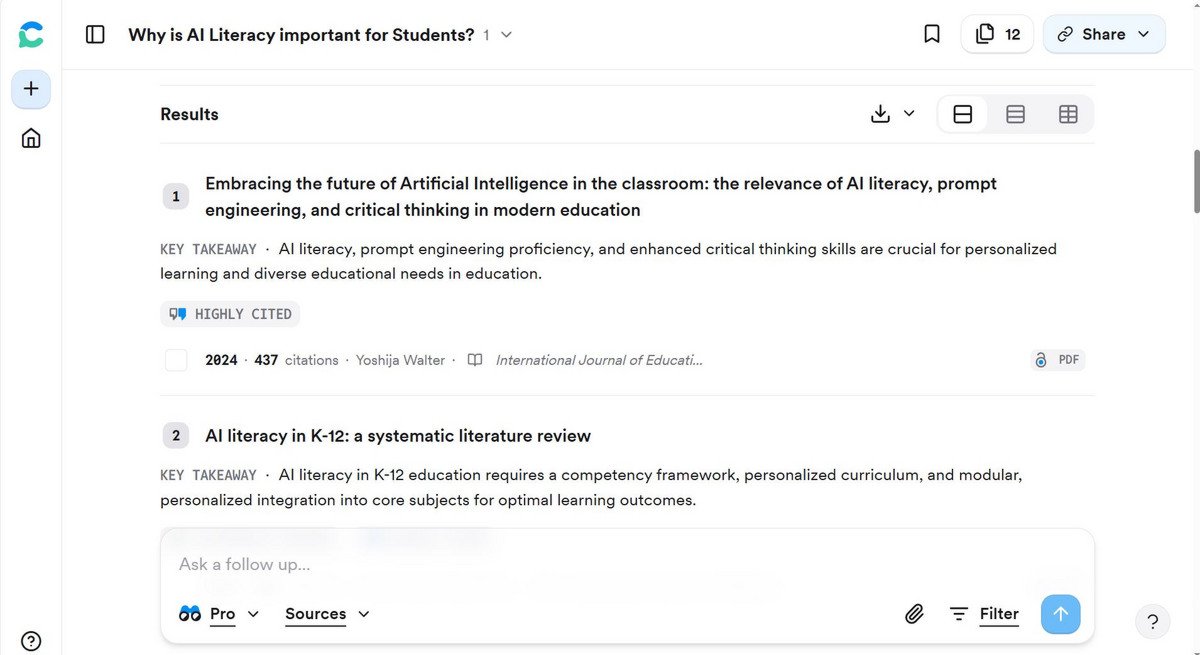
Finders identifizieren und priorisieren passende Literatur anhand von Suchbegriffen oder ganzen Fragestellungen.
Connectors stellen thematische Verbindungen zwischen Literaturtiteln her, indem sie diese analysieren und in Clustern gruppieren.
Finders funktionieren ähnlich wie digitale Bibliothekskataloge: Nutzende können Stichwörter, Phrasen oder sogar vollständige Fragen eingeben und erhalten dazu passende Treffer.
Diese Tools durchsuchen Metadaten, Abstracts und teilweise Volltexte, um relevante Publikationen zu identifizieren und zu gewichten.
Besonders hilfreich sind sie für die naturwissenschaftliche und medizinische Forschung, da sie vorwiegend englischsprachige Open-Access-Artikel mit DOI finden – weniger geeignet sind sie hingegen für Geistes- und Sozialwissenschaften, Theologie oder Jura.
Mit Finders lässt sich nicht nur passende Literatur entdecken, auch wenn die richtigen Fachbegriffe fehlen, sondern sie unterstützen auch beim Vergleichen, Zusammenfassen und Aufbereiten von Inhalten.
Automatisierte Zusatzfunktionen wie Generierung von Abstracts, tabellarische Extraktionen oder Hilfen beim Lesen (z.B. Hervorhebungen, Übersetzungen) können den Rechercheprozess beschleunigen.
Im Vergleich zu klassischen Datenbanken wie Web of Science, BASE oder Google Scholar bieten Finders zudem intuitivere, natürlichsprachige Suchanfragen und zeitsparende Zusammenfassungen.
Allerdings sind Paywall-geschützte Werke oder aktuelle nicht-englische Monografien kaum bis gar nicht auffindbar. Die Treffermenge ist oft kleiner als bei traditionellen Datenbanken – besonders, wenn es um kostenpflichtige oder fachspezifisch weniger abgedeckte Literatur geht.
Zudem sollte man die Nützlichkeit von manchen Zusatzfunktionen kritisch hinterfragen: Spielerische Features wie das Consensus Meter (zeigt auf Ja/Nein-Fragen die Bewertung durch die ca. 20 relevantesten Publikationen an) oder ‚Deep-Research‘-Funktionen können zwar einen schnellen ersten Überblick liefern, sind zumeist aber kostenpflichtig, auf OA-Artikel beschränkt, basieren auf intrasparenten Ranking-Methoden, und/oder liefern unvollständige bzw. verzerrte Zusammenfassung. Vor allem bei komplexen Fragestellungen können solche automatisierten Ergebnisse zu Fehlinterpretationen führen.
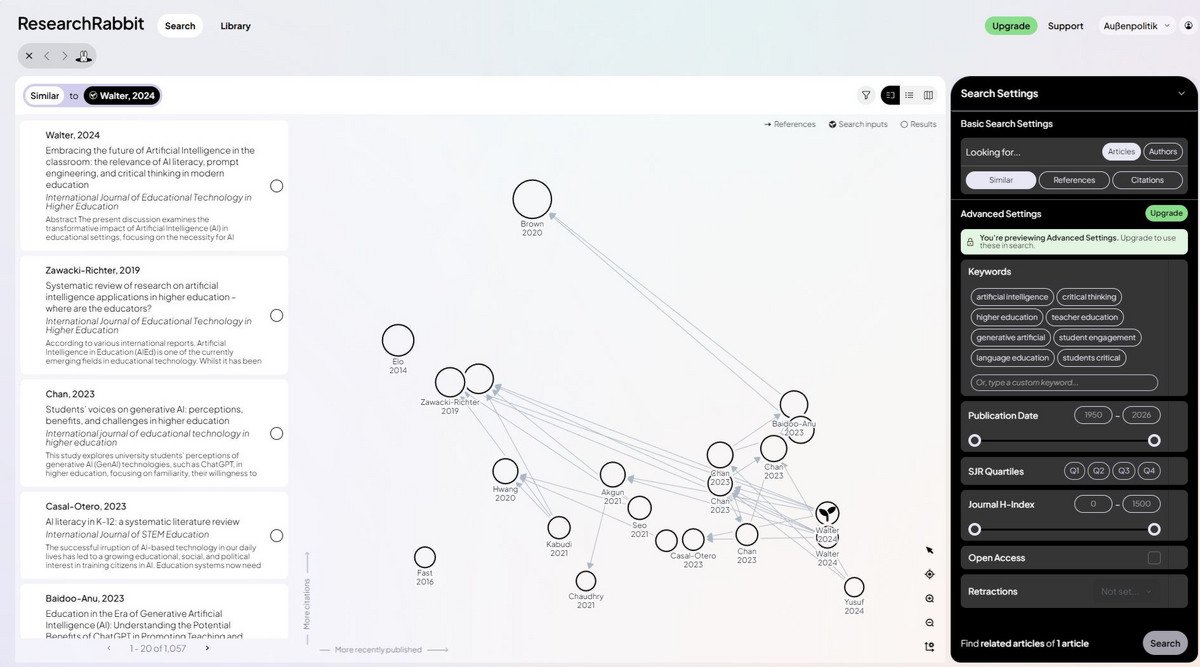
Connectors helfen dabei, thematisch verwandte Literatur auf Basis eines bereits bekannten Ausgangspapers („Seed Paper“) zu finden.
Damit ähnelt das Vorgehen der Recherche nach dem Schneeballsystem.
Ausgangspunkt ist stets ein Startdokument, das über DOI, Titel, Schlagwort oder eine hochgeladene PDF-Datei definiert wird. Darauf aufbauen identifiziert das Tool Publikationen, die in direkter oder indirekter Verbindung zum gewählten Text stehen – sei es durch wechselseitige Referenzen, thematische Nähe oder KI‑gestützte Ähnlichkeitsanalysen, die auch Verbindungen sichtbar machen, die bibliografisch nicht unmittelbar erkennbar sind.
Die Ergebnisse werden dann in einer visuellen, thematisch gruppierten Cluster präsentiert, was komplexe Forschungsschwerpunkte und Netzwerke von Autorinnen und Autoren auf einen Blick erkennbar macht. Besonders für Geistes- und Sozialwissenschaften bieten sie einen intuitiven Einstieg.
Connectors finden bibliograpfisch verknüpfte Publikationen, die z. B. in Crossref, OpenAlex oder Open Citations registriert sind. Ihr besonderer Mehrwert liegt in der systematischen Literaturrecherche, dem Erkennen von Kooperationsstrukturen oder der Identifikation von Literatur, die über mehrere Zwischenstationen mit dem Ausgangstext verbunden ist.
Zudem erleichtern die grafischen Darstellungen den Einstieg in neue Themenfelder und bieten ein intuitives Navigieren durch bibliografische Netzwerke.
Einige Tools – etwa das kostenpflichtige Scite – gehen noch weiter, indem sie auf Volltexte zugreifen und präzise markieren, wie ein Werk an einer bestimmten Textstelle zitiert wird („Citation Statements“), was eine differenzierte Einschätzung wissenschaftlicher Diskurse ermöglicht.
Gleichzeitig bestehen klare Grenzen: Die Qualität der Ergebnisse hängt stark vom jeweiligen Forschungsfeld und der zugrunde liegenden Datenlage ab.
Ältere Werke ohne dauerhafte Identifikatoren, Publikationen mit spärlichen Metadaten oder ausschließlich gedruckte Literatur werden nur unzureichend erfasst, was die Aussagekraft der Netzwerke mindert.
Zudem stehen häufig nur wenige Filteroptionen zur Verfügung, sodass Literaturangaben manuell überprüft und korrigiert werden müssen, da sie teilweise unvollständig oder fehlerhaft sind. Eine automatische inhaltliche Zusammenfassung fehlt oft, auch wenn vorhandene Abstracts angezeigt werden.
Im Vergleich zu etablierten Diensten wie Google Scholar bieten Connectors daher keinen quantitativen Vorteil, sondern vor allem eine alternative, visuelle Perspektive auf vorhandene Datenbestände.
Beispiele für Connectors sind u. a.:
Die Nutzung generativer KI im Studium und Forschung erfordert eine nachvollziehbare Kennzeichnung und Dokumentation, um sowohl die eigene Arbeitsweise transparent zu halten als auch wissenschaftlichen Standards gerecht zu werden.
Werden Texte mit KI-Tools generiert, müssen sie stets als solche ausgewiesen werden, sonst kann die Einstufung als Täuschungsversuch drohen. Auch wenn die Regelungen für die KI-gestützte Literaturrecherche oft weniger strikt sind, empfiehlt sich auch hier die klare Offenlegung des Einsatzes, vor allem wenn die KI bei zentralen Arbeitsschritten wie der Literaturauswahl oder der Dokumentenanalyse zur Anwendung kam.
Entscheidend ist, dass die wissenschaftliche Arbeit eine eigenständige Leistung bleibt, bei der Studierende und Forschende die Verantwortung für Inhalt und Korrektheit tragen. Da die Anforderungen zwischen Disziplinen und Lehrstühlen variieren, sind stets die Vorgaben der betreuenden Dozierenden zu beachten.
Die folgenden Ausführungen sollen lediglich als Orientierungshilfe dienen und können sowohl einzeln als auch kombiniert verwendet werden:
Die Richtlinien verbreiteter Zitationssysteme (APA, MLA, Chicago Style) bieten Orientierung, um KI-generierte Passagen als direkte oder indirekte Zitate kenntlich zu machen.
Zweck:
Beispiel im APA Style aus folgendem APA-Artikel:
In der Einleitung, dem Methodenteil oder in Fußnoten lässt sich erläutern, wie KI in einzelnen Phasen des Forschungsprozesses (z. B. Literaturrecherche, Ideenfindung, Textgenerierung oder Textüberarbeitung) zum Einsatz kam.
Zweck:
Beispiel Dokumentation des KI-Einsatzes bei der Forschungsfrage:
Eine kurze Erläuterung, wie KI den Forschungsprozess beeinflusst hat, kann im Schlussteil der Arbeit stehen. So kann die KI-Unterstützung richtig eingeordnet und auf mögliche Limitationen hingewiesen werden.
Zweck:
Beispiel im Fazit/Diskussionsteil:
Eine separate Dokumentation im Anhang ermöglicht eine strukturierte Übersicht über den KI-Einsatz, etwa in tabellarischer Form mit Angaben zu Arbeitsschritt, genutztem Tool und Ergebnis.
Zusätzlich sollten KI-generierte Inhalte lokal gespeichert werden, um sie später nachvollziehen zu können. Dies ist besonders bei längeren Prozessen wichtig, wo sonst der Bezug zum ursprünglichen Input verloren gehen könnte.
Zweck:
Beispiel
Der Einsatz von KI-Tools wirft nicht nur technische und rechtliche Fragen auf, sondern erfordert auch eine sorgfältige ethische Auseinandersetzung. Hinter vielen KI-Systemen stehen komplexe Trainingsprozesse, die teilweise unter problematischen Arbeitsbedingungen, insbesondere im Globalen Süden, stattfinden. Zudem ist der ökologische Fußabdruck von KI-Anwendungen nicht zu unterschätzen – vor allem leistungsstarke Modelle verbrauchen erhebliche Mengen an Energie und Ressourcen (Tagesschau, 3.12.25).
Neben diesen Herausforderungen gilt es zu hinterfragen, wie KI-gestützte Ergebnisse in die wissenschaftliche Praxis einfließen, ohne dass dadurch Verzerrungen entstehen oder die Integrität der Forschung beeinträchtig wird. Eine kritische Reflexion über die Folgen von KI im Forschungsprozess ist daher unerlässlich, um verantwortungsvoll mit dieser Technologie umzugehen.

Um den Herausforderungen bezüglich KI zu begegnen, etablierte sich AI Literacy als interdisziplinärer Ansatz. Im Zentrum steht dabei die Vermittlung von Wissen und Fertigkeiten, um KI-Systeme kritisch zu hinterfragen, mit ihnen zusammenzuarbeiten und sie in verschiedenen Lebensbereichen praktisch anzuwenden.
Im Sinne der Informationskompetenz ist der Umgang mit KI daher ein wichtiges Aufgabenfeld der Universitätsbibliothek.
AI Literacy wird definiert als „a set of competencies that enables individuals to critically evaluate AI technologies; communicate and collaborate effectively with AI; and use AI as a tool online, at home, and in the workplace.” (Long/Magerko 2020, S. 2)
Mit der Verabschiedung des EU AI Act im Mai 2024 hat die Europäische Union einen verbindlichen Rechtsrahmen für den Einsatz Künstlicher Intelligenz geschaffen. Die Regelungen folgen dabei einem ‚risikobasierten Ansatz‘, wonach Anwendungen, deren Risiko als höher eingeschätzt wird, auch strengeren Auflagen unterliegen. Zudem besteht eine Transparenzpflicht, d.h. KI-generierte Inhalte müssen entsprechend gekennzeichnet werden.
Es sollten bei ChatGPT und Co. keine persönlichen, sensiblen oder vertraulichen Daten eingegeben werden. Zum einen werden Eingaben oft für Trainingszwecke gespeichert. Zum anderen werden die meisten KI-Systeme außerhalb der EU gehostet, wodurch eine DSGVO-konforme Nutzung oft nicht gewährleistet werden kann.
Während die Eingabe von bibliographischen Angaben in KI-Tools unproblematisch ist, gilt das Hochladen von geschützten Forschungsdaten oder Werken (E-Books, Aufsätze, Rezensionen, etc.) als Verstoß gegen das Urheberrecht. Nur wenn die Literatur gemeinfrei ist oder unter einer CC0-Lizenz veröffentlicht wurde, darf es mit KI verwendet werden. Prüfen Sie also stets die Nutzungsbedingungen, um Urheberrechtsverletzungen zu vermeiden!
KI-gestützte Systeme generieren Ergebnisse auf Grundlage umfangreicher, aber häufig intransparenter Datenbestände. Oft ist nicht nachvollziehbar, welche Quellen genutzt wurden, da die Datengrundlage nur begrenzt offengelegt wird.
Viele Tools analysieren vorwiegend freiverfügbare, englischsprachige Literatur, während aktuelle oder fachspezifische Inhalte mitunter unberücksichtigt bleiben. Zudem können kostenpflichtige Ressourcen wie E-Books, Zeitschriften oder Datenbanken in den Ergebnissen fehlen.
Die Eignung der Tools variiert demnach je nach Fachgebiet und Sprache.
Ein weiteres, nicht zu unterschätzendes Problem ist die Verzerrung (Bias) der Modelle: KI-Systeme reproduzieren oft Vorurteile oder tendenziöse Muster aus den Trainingsdaten, was zu unsachlichen, voreingenommen oder diskriminierenden Ausgaben führen kann.
Hinzu kommt, dass KI-Tools häufig scheinbar plausible, aber tatsächlich frei erfundene Aussagen generieren (Tagesschau, 27.10.2025). Da die Quellen solcher Fehler oft nicht nachvollziehbar sind, können Nutzende diese kaum erkennen. Diese sog. "Halluzinationen" verschärfen die bereits bestehenden Herausforderungen durch Bias, da die KI nicht nur vorhandene Verzerrungen reproduziert, sondern zusätzliche Ungenauigkeiten hinzufügt.
KI-Tools bieten häufig eine kostenlose Basisversion an, wobei meist eine Registrierung erforderlich ist, um sie nutzen zu können. Wer zusätzliche Funktionen möchte, stößt oft auf kostenpflichtige Upgrades oder Abonnements.
Bevor Sie sich für ein Tool entscheiden, sollten Sie also abwägen, welche Funktionen für die Aufgabenstellung wirklich notwendig sind und welches Preismodell zu Ihren finanziellen Mitteln passt.
KI-Systeme können Teilbereiche des wissenschaftlichen Arbeitens erleichtern, sollten jedoch nicht als unfehlbare Lösung gesehen werden! Studierende sollten zudem immer die Vorgaben ihrer Dozierenden und die Prüfungsregularien Ihres Fachs bezüglich des KI-Einsatzes berücksichtigen.
Es werden selten alle relevanten Titel von KI-Tools erfasst. KI-genierte Inhalte können daher nicht zitierfähig sein, fehlerhafte Referenzen enthalten (z. B. falscher Journalnamen) oder gar nicht existieren (auch wenn sie auf den ersten Blick so wirken). Zudem können sie nicht immer optimal auf wissenschaftliche Standards ‚aligniert‘ sein, was zu unbeabsichtigten und verzerrenden Ergebnissen führen kann.
Nutzen Sie diese Technologie also stets mit großer Sorgfalt, seien Sie sich der rechtlichen und ethischen Rahmenbedingungen bewusst und hinterfragen Sie jeden Output kritisch.
Unter Berücksichtigung dieser Aspekte, können KI-Tools nützliche Hilfsmittel bei der Literaturrecherche und im wissenschaftlichen Arbeiten sein.
Künstliche Intelligenz (KI) bezeichnet Systeme, die menschenähnliche kognitive Fähigkeiten nachahmen - von Spracherkennung und Textgenerierung bis hin zur Entscheidungsfindung und Problemlösung. Diese Technologien bieten vielversprechende Ansätze für die wissenschaftliche Arbeit, erfordern jedoch auch einen kritischen Umgang.
Generative KI ist der Oberbegriff für alle KI-Systeme, die trainierte statistische Modelle nutzen, um eigenständig neue Inhalte wie Texte, Bilder, Audio, Code oder Videos zu erzeugen.
Large Language Models (LLMs) wie ChatGPT oder Open WebUI sind spezialisierte Formen Generativer KI, die Texte verstehen, verarbeiten und erzeugen können. Sie wurden mit einer enormen Menge an Textdaten trainiert und haben dabei Milliarden von Wortkombinationen analysiert. LLMs generieren die Antworten ausschließlich durch statistische Vorhersagen innerhalb des vorgegebenen Anfragekontexts (dem sog. Prompt). Da sie Sprache lediglich als Wahrscheinlichkeitsmuster interpretieren, fehlt ihnen kritisches Denkvermögen und ein echtes Sprachverständnis, weshalb sie auch als „stochastische Papageien“ (Bender et al. 2021) bezeichnet werden.
Retrieval-Augmented Generation (RAG) kann die KI-gestützte Literaturrecherche verbessern, indem große Sprachmodelle mit externen Datenquellen wie Forschungspapers (z.B. aus PubMed) oder eigenen PDF-Sammlungen verknüpft werden. So entstehen präzisere, faktenbasierte Ergebnisse, während das Risiko falscher oder erfundener Aussagen ("Halluzinationen") sinkt. Dieses Verfahren kommt bereits bei KI-Tools wie Perplexity, Elicit oder Semantic Scholar zum Einsatz. Die Qualität der Ergebnisse hängt dabei von den zugrundeliegenden Daten ab und erfordert weiterhin eine kritische Überprüfung.










